
Как измеряется количество информации?
Автор: Дон Баттен (англ. Don Batten)
Источник: creation.com
Перевод: Владимир Матвеев
Редактура: Владимир Силенок
Ответ на письмо Стивена Гальперина (Stephen Halperin) (Чешская Республика), позволившего использовать свое полное имя. Сначала Его письмо было опубликовано полностью, а затем доктор Дон Баттен (Don Batten), работающий в Международной Службе Креационизма в Австралии, ответил на него разбив по пунктам как если бы это было общение через почту.
Дорогие друзья,
На вашей интернет-странице вы говорите следующее:
«Количество информации измеряется не числом характеристик, но величиной, называемой специфической сложностью последовательности оснований или последовательности белковых аминокислот.»
У меня возникли следующие вопросы:
- Как вы измеряете специфическую сложность?
- Поскольку ДНК кодирует белки, какова взаимосвязь между вашим определением сложности и числом генов содержащихся в ДНК?
- Вы также утверждаете, что мутации уменьшают сложность. Если мутация приводит к замещению одной аминокислоты (например аланина на лейцин), или вызывает удвоение ДНК, почему это называется уменьшением количества информации?
Дорогие друзья,
На вашем веб-сайте вы говорите следующее:
«Количество информации измеряется не числом характеристик, но величиной, называемой специфической сложностью последовательности оснований или последовательности аминокислот белка.»
У меня возникли следующие вопросы:
-
Как вы измеряете специфическую сложность?
Дорогой Стивен,
Специалист по теории информации, Ли Спетнер (Lee Spetner), определяет термин специфическая сложность как математически-термодинамическое понятие в публикации “Ли Спетнер: Диалог с Эдвардом Максом (Lee Spetner/Edward Max Dialogue)”. Ниже я привожу выдержку из его статьи (НДТ = нео-дарвинистская теория):В моей книге «Не по воле случая» (“Not by Chance”), я не определил количество приобретенной или потерянной информации в результате одной мутации. Я этого не сделал, в основном, потому что мне не хотелось приводить уравнения, тем самым отпугнув среднестатистического читателя. И в любом случае, мне казалось очевидным, что мутация, которая нарушает функцию гена (например, гена-репрессора), приводит к потере информации. Я также посчитал очевидным фактом то, что мутация, которая снижает специфичность фермента тоже является потерей информации. Но я использую возникшую теперь возможность, чтобы выразить количественно разницу в информации до и после мутации на примере одного важного случая, который я описал в моей книге.
Объем информации генома трудно оценить с каким-то уровнем точности. К счастью, для моих целей, мне нужно будет рассмотреть только изменение информации в ферменте, вызванное мутацией. Объем информации фермента является суммой многих составляющих, включая:
- Уровень каталитической активности
- Специфичность в отношении субстрата
- Сила связи с клеточной структурой
- Специфичность связи с клеточной структурой
- Специфичность последовательности аминокислот, предназначенная для определения подверженности фермента к деградации
Все эти свойства трудно оценить, но наиболее легким подходом является определение информации по специфичности субстрата.
Чтобы оценить информацию в ферменте, я приму допущение, что объем информации самого фермента является, по крайней мере, максимальным количеством информации приобретенной при переходе субстратного распределения в распределение продукта. (Я думаю, что это допущение имеет смысл, но для большей точности его необходимо доказать). Мы можем говорить о большей субстратной специфичности фермента как о фильтре. Энтропия смеси веществ разделенных фильтрованием меньше, чем энтропия первоначальной смеси. Следовательно, мы можем утверждать, что процесс фильтрации приводит к возрастанию информации на величину, равную уменьшению энтропии. Давайте представим себе однородное распределение субстратов доступное многим копиям фермента. Я выбрал однородное распределение субстратов потому что это позволит ферменту реализовать свое максимальное увеличение информации. Рассматриваемые здесь субстраты ограничены набором сходных молекул, на которые фермент оказывает одинаковое метаболическое влияние. Это ограничение не только упрощает наш пример, но оно также применимо к случаю, обсуждаемому в моей книге.
Продукты субстрата в отношении которых фермент более активен, будут более многочисленными, чем продукты того субстрата, в отношении которых фермент менее активен. Из-за фильтрации, распределение концентрации продуктов будет иметь более низкую энтропию, чем энтропия субстратов. Заметьте что мы игнорируем всякое изменение энтропии, вытекающее из химических превращений субстратов в продукты, и мы фокусируем внимание на изменение энтропии, которое отражено в распределениях продуктов субстратов испытавших влияние ферментов.
Энтропия совокупности состоящей из n элементов с относительными концентрациями равными f1,…, fn описывается следующим уравнением:![]() (1)
(1)
Eсли основание логарифма равно 2, тогда единицами энтропии будут биты.
В качестве первого пояснения этой формулы, давайте рассмотрим крайний случай с nвозможными субстратами из которых только один субстрат подвержен не-нулевому влиянию фермента. Это пример совершенного фильтрования. Входная энтропия однородного распределения n элементов согласно уравнению (1) будет равна.
![]()
(2)
поскольку каждое значение fi равно 1/n. Энтропия на выходе равна нулю,![]()
(3)
поскольку все концентрации кроме одной равны нулю, а концентрация одной равна 1. Тогда уменьшение энтропии, вызванное селективностью фермента будет равно разнице между (2) и (3), или
![]()
Еще один пример – это другой крайний случай, в котором фермент не различает nсубстратов. Здесь энтропия на входе и выходе одинаковая, то есть
![]()
(4)
Таким образом, увеличение информации, которая является разницей между H0 и HI, равно нулю,
![]()
(5)
Мы нормализуем активности фермента на разных субстратах и эти нормализованные активности теперь будут частичными концентрациями продуктов. Такая нормализация устранит из нашего рассуждения влияние уровня абсолютной активности на объем информации, оставив только эффект выборочности.
Хотя такие упрощения не позволяют нам рассчитать общее уменьшение энтропии, вызванное действием фермента, нам удается рассчитать изменение энтропии обусловленное одним лишь эффектом специфичности фермента.
Опасность поспешных выводов
Спетнер: В качестве последнего примера, позвольте мне рассмотреть некоторые из серии примеров, которые я обсуждал в моей книге, и которые показывают опасность поспешных выводов. Этот предмет заслуживает внимания, потому что эволюционисты со времен Дарвина виноваты в скороспелых и необоснованных выводах основанных на неадекватных данных. Для иллюстрации моей мысли, я возьму здесь только часть дискуссии из моей книги, а именно, то место которое я заимствовал у Burleigh et al. 1974, Biochem. J. 143: 341.
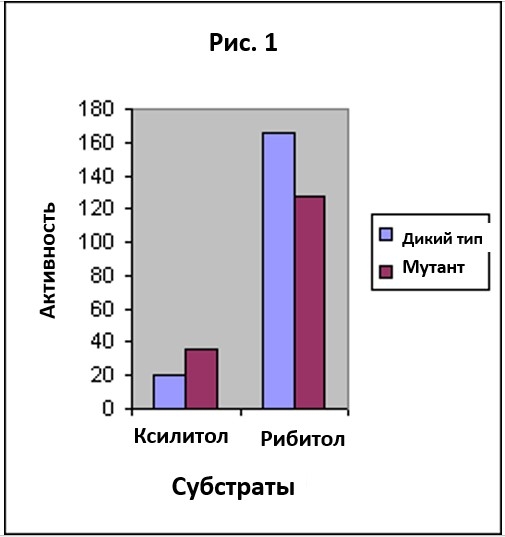
Рибитол – это сахар, который встречается в природе и может расщепляться некоторыми бактериями в почве, а рибитол-дегидрогеназа – это фермент, который катализирует первую ступень этого метаболизма. Ксилитол- это сахар, очень похожий по структуре на рибитол, но в природе он не встречается. В нормальных условиях, бактерии не могут жить на ксилитоле, но когда большую популяцию культивировали только на ксилитоле, то появлялись мутанты, способные к метаболизму ксилитола. Был найден фермент дикого типа, который мог немного воздействовать на ксилитол, нo не в такой мере, чтобы бактерии могли существовать на диете, состоящей из одного только ксилитола.
Мутированый фермент обладал достаточной силой, чтобы позволить бактерии жить на чистом ксилитоле. Рис. 1 показывает активность фермента дикого типа и мутированного фермента на рибитоле и ксилитоле. Заметьте, что по сравнению с ферментом дикого типа, мутированный фермент обладает более низкой активностью на рибитоле и более высокой на ксилитоле. Эволюционист может поддаться соблазну усмотреть здесь начало некоторого прогресса. Он может поторопиться с выводом, посчитав, что если возникнет серия подобных мутаций следующих одна за другой, то эволюция произведет фермент, который будет высоко активным на ксилитоле и низко активным или неактивным на рибитоле. Не принесет ли это пользу бактерии, у которой в распоряжении есть только ксилитол, но нет рибитола? Такая серия могла бы произвести эволюционное изменение, как раз такое, о котором говорит НДТ. И это будет примером серии которая подтвердит НДТ. Серия будет состоять из мутаций, которые постепенно понизят активность фермента на первом субстрате и повысят на втором. Но Рис. 1 в данном контексте вводит нас в заблуждение, потому что он описывает только одну ограниченную сторону дела. Берлей и его коллеги также измерили активности двух ферментов на другом подобном сахаре, L-арабитоле, и результаты этих измерений показаны на Рис. 2. Картина меняется, если добавить данные по L-арабитолу. Мы больше не видим, чтобы мутация переключала активность с рибитола на ксилитол. Вместо этого, мы видим общее понижение выборочности фермента в отношении группы субстратов. Профили активности на Рис. 2 показывают, что фермент дикого типа более выборочен, чем мутантный фермент.
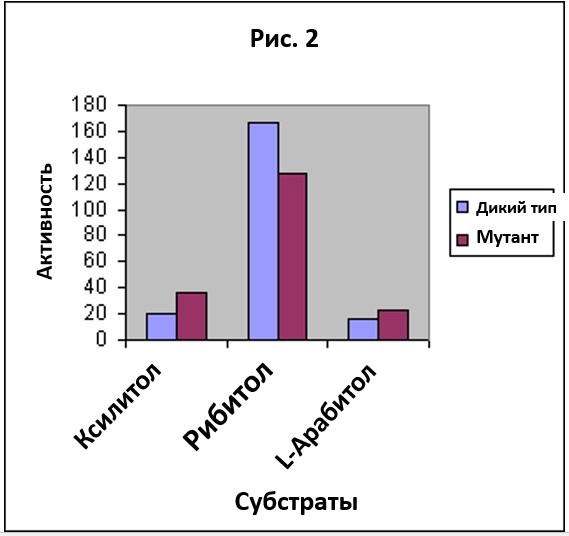
На Рис. 1 прослеживается тенденция к эволюции фермента с высокой активностью в отношении ксилитола и низкой по рибитолу. Но Рис. 2 показывает, что такая экстраполяция необоснована. Напротив, он показывает совершенно другую тенденцию. Экстраполяция тенденции, наблюдаемой на Рис. 2 показала бы, что серия таких мутаций могла бы привести к ферменту у которого выборочность полностью отсутствует, а он обладает одинаково низкой активностью в большом диапазоне субстратов.
Этот пример показывает, что поспешная экстраполяция выводов, основанных на кажущейся тенденции — дело рискованное. Когда в распоряжении мало данных, кажется, что мутация добавляет информацию в ферменте. Но рассмотрение небольшого количества новых данных указывает на то, что мутация приводит к деградации специфичности фермента и потере информации. Подобно тому, как мы подсчитали количество информации в двух отдельных вышеупомянутых случаях, мы можем оценить количество информации для обоих типов ферментов, как дикого типа так и мутанта, когда они действуют на однородную смесь трех субстратов. Если мы используем значения активности, полученные Берлей с соавторами, то мы обнаружим, что количество информации для специфичности двух ферментов равны 0.74 и 0.38 бит, соответственно. Таким образом, получается что информационное содержание у фермента дикого типа вдвое выше, чем у мутанта.
Эволюционное сообщество, со времен Дарвина и до сегодняшнего дня, основывало свои утверждения на преждевременных, неоправданных выводах. Дарвин наблюдал, как селекционеры могут произвести путем отбора большое разнообразие голубей, и на основании этого, он предполагал что возможности селекции неограниченны. Эволюционисты, видевшие выведение сельскохозяйственных растений и животных со многими полезными для продажи признаками, делали поспешный вывод, что естественный отбор в течение миллионов лет способен привести к адаптивным изменениям во много раз большим, чем искуственный отбор в течение десятков лет. В моей книге я показал, что такие экстраполяции плохо обоснованы потому что эксперименты по скрещиванию, которые, например, повышают у пшеницы содержание белка или увеличивают размеры овощей, порождаются мутациями, которые разрушают гены-репрессоры. Преждевременные выводы оказались ложными, потому что были основаны на данных, которые нельзя было экстраполировать по отношению к длинным последовательностям. Невозможно увеличить информацию за счет длинной последовательности ступеней, каждая из которых теряет информацию. Как я уже отметил в моей книге, такая ситуация напоминает продавца, который потерял немного денег на каждой продаже, но думал, что приобрел много за счет увеличения объема продаж.
2) Поскольку ДНК кодирует белки, какова взаимосвязь между вашим определением сложности и числом генов содержащихся в ДНК?
Конечно существует грубая связь между числом белков закодированных в последовательности ДНК и уровнем специфической сложности. Но оценки «числa генов» очень приблизительны. Например, считается, что ДНК человека содержит 25 000 «генов», между тем, человеческая клетка может произвести более 100 000 белков (по разным оценкам – до 150 000 или даже больше). Очевидно, что еще многое не известно о том как 25 000 «генов» могут произвести так много разных белков. Более точной мерой специфической сложности данного генома могло бы быть число закодированных белков. Однако, помимо этого, большое количество информации не участвует напрямую в производстве белков – например белки структуры хромосомы. Колоссальное количество информации также, по-видимому, записано в последовательностях, определяющих стадии развития организма – сфера исследований, в которой почти все остатся неизвестным. Также возможно существование последовательностей, проверяющих генетические ошибки, и т.д. и т.п. Сегодняшных знаний пока что недостаточно чтобы описать все функции последовательностей ДНК, которые необходимы для должного измерения информации.
3) Вы также постулируете, что мутации уменьшают сложность. Если мутация приводит к замещению одной аминокислоты (например аланина на лейцин), или вызывает удвоение ДНК, почему это называется уменьшением количества информаци
Пример, который объсняет рассмотренные выше принципы, приводится у Спетнера. Однако, единичная мутация не обязательно приводит к уменьшению специфической сложности – просто отдельный случай положительного мутирования и высокая вероятность повреждения не могут быть механизмом производящим огромное количество специфической сложности, наблюдаемой у живых организмов. Тот факт, что мутации известны прежде всего благодаря дефектам, которые они вызывают, служит свидетельством их преобладающей тенденции разрушать информацию в живых организмах (подобно тому, как орфографическая ошибка сделанная во время печати на клавиатуре моего компьютера уменьшит количество информации, содержащейся в моем тексте). Спетнер также обсуждает тему дупликации гена на приведенной выше ссылке. Однако, только представьте — если Вы купили две копии газеты, значит ли это, что Вы купили вдвое больше информации? Конечно нет. Дупликация чего бы-то ни было не приводит к увеличению количества информации. Случайные мутации, приведшие к изменению дуплицированного гена не добавят информации, разве что мутировавшая последовательность стала кодом для нового, полезного белка. Например, если бы слово «супермен» было бы «геном», претерпевшим дупликацию, а мутации изменили буквы на «скикваут», то вы определенно потеряли информацию, хотя и приобрели новую последовательность. В этом и состоит разница между сложностью и специфической сложностью. Горка песка – сложное образование, но она не содержит особой информации, потому что в ней отсутствует специфика, а сама по себе она ничего не означает.
Я надеюсь, что это поможет.
Дон Баттен
Если вам понравилась статья, поделитесь ею со своими друзьями в соц. сетях!
ВАМ БУДУТ ИНТЕРЕСНЫ ЭТИ СТАТЬИ:






